Skip to main content
Search
Search
Microboids
Sharing Knowledge improves Knowledge... Knowledge should come at as less cost as possible.
Blog
Posts
More…
Posts
Showing posts from June, 2012
Show All
Posted by
Varun C N
June 25, 2012
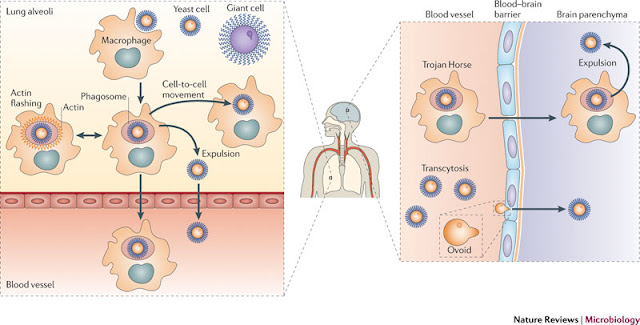
Clash of the titan- Survival strategy for Cryptococcus
Posted by
Varun C N
June 18, 2012
Pore-fection aims perfection
Posted by
Varun C N
June 12, 2012
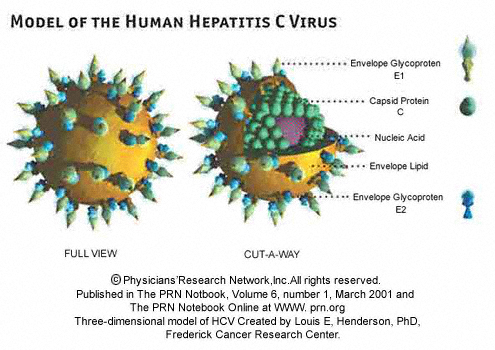
The mi-RNA game of HCV
Posted by
Varun C N
June 04, 2012
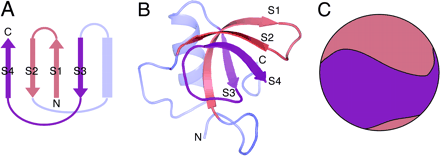
Hydrophobins- A snapshot
Newer Posts
Older Posts
Home